Softball is a stats heavy sports. When looking at these stats, people make an "implicit" assumption that a team with "better" stats have higher chance of winning more games, hence resulting in a higher rank at the end of the season. But is it really true?
While several game stats are recorded and updated weekly, a team's strength relative to the other teams are calculated using only the binary outcomes (win or loss) to determine its rank during the season. In other words, in order to quantify a team's strength, RPI (Rank Percentage Index) is used, which is a weighted sum of a team's win percentage (WP), a its opponents' WP, and its opponents' opponents' WP:
RPI = 0.5 WP (Team) + 0.25 WP (Opponents) + 0.25 WP (Opponents' opponents)
The rationale behind this recursive formula is that a team that played against more competitive teams would have lower WP. This leads to another question regarding stats: does playing against more competitive team hurt the stats as well?
Looking at how the teams are ranked while the stats don't seem to have direct utility although its availability suggests that these stats are somehow informative, I decided to investigate how "informative" these stats actually are in predicting a team's performance at the end of the season. These end-of-season performances include final RPI ranking, NCAA (National Collegiate Atheletic Association) tournament appearance, NCAA tournament ranking, and WS (World Series) tournament appearance and finish.
League Structure & Schedule
There are more than 1,500 college softball teams in the United States. These teams are split into 32 Conferences based on geography. There are 5 divisions, NCAA Division I/II/III, NAIA (National Association of Intercollegiate Athletics), and NJCAA (National Junior College Athletic Association), with ~300 teams playing in each division. This project focused on NCAA Division I since NCAA DI is where top teams compete and receive the most attention.
NCAA DI repeat the following schedule every year:
Regional matches: February ~ May
NCAA Tournament of 64: May ~ June
WS Tournament of 8: June
Every year, new season starts in February with regional matches. During this time, about 2/3 of the matches are within Conference games. Near the end of the season, all teams are ranked with RPI, and top 64 teams are chosen* to compete in NCAA Tournament. Following the game brackets, surviving 8 teams enter WS Tournament, finalizing the champion team in June.
* top 64 are chosen chosen by a committee, and sometimes a team outside the rank 64 gets chosen after some adjustments.
Project Workflow Overview

In order to develop predictive models, information about the teams as well as the performance outcome measures were scraped from stats.ncaa.org and NCAA.com using Selenium since both sites run on dynamic API. NCAA softball team stats were available between 2013 and 2019. After basic cleaning up (team name unification), basic EDA was performed to observe the data structure, and then feature engineering was performed to prime the input variables to be compatible with the machine learning models. Proper imputation was performed to fill in the missing values as some stats were discontinued or created between 2013 and 2019.
Once the input variables were preprocessed, 3 different models were developed to predict (Model 1) RPI ranking, (Model 2) NCAA Tournament appearance, and (Model 3) NCAA/WS Tournament Ranking. For Model 1, regression model was used to predict continuous integer ranking, for Model 2, binomial classification model was used to predict in/out outcomes, and for Model 3, multinomial classification model was developed to predict different rank classes (e.g. champion, finalist, semi-finalist, etc.).
Aside from the technical objective of verifying whether aggregated stats are sufficient in predicting the end-of-season performances, the social aspect of the motivation was to increase interest and support for women's softball if not women's sports in general (Blog post: Seed Project & Motivation) Therefore, transfer of information is an important objective, and to achieve this goal, an interactive app was also developed to provide information about a team's past and current performance as well as predictions for the future events.
Data Collection - Webscraping
Stats were scraped from stats.ncaa.org and nca.com using Selenium. The table below summarizes the data frame that contains input variables and index. Stats are updated every week or two, and they are aggregated averages from all the games played prior to the date. Since one of the technical objective was to investigate whether aggregated stats are sufficient in predicting a team's performance outcomes, only the end of the season stats were gathered. Softball stats can be largely divided into 3 categories: (1) offensive, (2) defensive, and (3) outcome. In softball, the batting team plays offense while the pitching team plays defense. Offensive stats are Batting Average, Slugging Percentage, Scoring, Doubles per Game, Triples per Game, Home Runs per Game, Stolen Bases per Game, and On Base Percentage (please see Description column for the definitions). Defensive stats are Double Plays per Game, Hit Batters, Strikeout to Walk Ratio, Fielding Percentage, Earned Run Average, Shutouts, Team Strikeouts per Seven Innings. Lastly outcome stats include Win Loss Percentage.

Blog post: Webscraping with Selenium (TBU)
Modeling
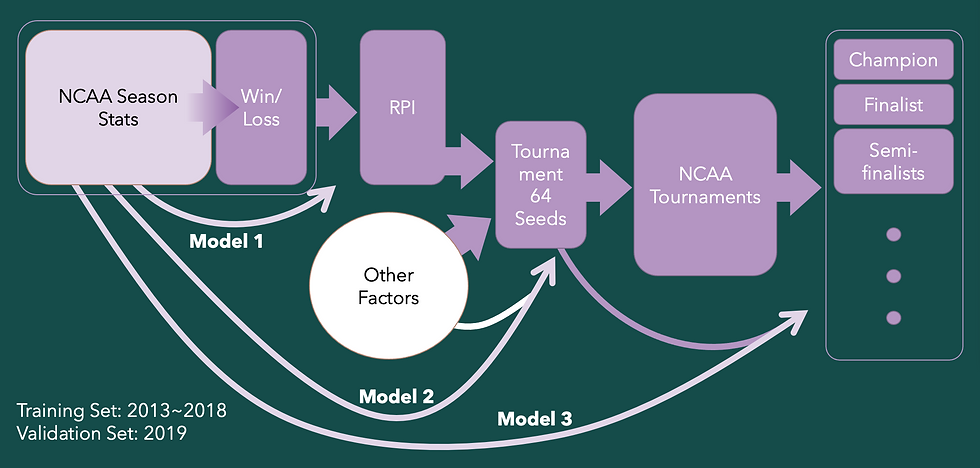
The block diagram below shows how the game information flow (rectangle blocks with arrows) and models 1, 2, and 3 are related. While the NCAA stats are recorded and updated, RPI is calculated based on the Win/Loss record. Based on the RPI and other factors, 64 teams are chosen to enter NCAA Tournament. And then 8 surviving teams enter WS to compete for the championship. Contrary to sequential event flow in the real world, the models are independently developed to find the relationship between its inputs and outputs. Specifically, while the inputs remain the same, the target outputs are different, and different relationships are found for each of these outputs.
Models were trained/tested using data from year 2013~2018 and validated using data from year 2019.
EDA & Feature Engineering
Exploratory data analysis was performed in order to select proper modeling approaches. Correlation analysis revealed that there are strong intercorrelations (|rho| > 0.6) among the input variables (game stats). Because of such high intercorrelations, which are visible in the pair plots below as linear trends, regression/classification models will suffer from multicollinearity, making models difficult to interpret. In order to resolve multicollinearity, factor analysis for mixed data (FAMD) was performed to tranform features into orthogonal space. FAMD was chosen over principal component analysis (PCA) since conferences are categorical variables while other stats are numerical variables. FAMD components were then used as input variables to the game projection models described in this post. Details of FAMD will be covered in a separate future blog post.

Blog post: FAMD (TBU)
[Model 1] RPI Ranking
At the end of the regionals, we want to see which teams are strong to predict the champion of the season (winner of the WS tournament). To visualize each team's relative strength, all teams are ranked according to their RPIs. Then given the stats, can we predict what a team’s most likely RPI ranking given its stats and conference?

Since RPI ranks are continuous integer numbers, linear regression model (RPI ~ FAMD components) was developed for Model 1. Also, inverse logistic transformation was applied to RPI ranking to satisfy the linearity assumption.
Left figures show the validation data's RPI vs predicted RPI (top) and the model's residuals (bottom). It can be seen that the residuals are normally distributed around 0, indicating that the regression was performed properly. More importantly, the variance explained (R2) shows that 90.4% of the variance in 2019 can be explained by the model and its inputs, stats and conferences.
Since the model outputs inverse logistic transformation of the ranks, the output was transformed back into ranks by sorting teams according to the output.
[Model 2] NCAA Tournament of 64 Appearance

Out of approximately 300 teams, top 64 teams make into the NCAA tournament at the end of the season each year. Will my favorite team make into the tournament? To answer this question, a model to predict the likelihood of a team's making the top 64 was developed using Stochastic Gradient Descent classifier with logistic function as the link function. Here, although the model is a binomial classifier, it is technically a logistic regression: 64 in/out (1/0) ~ FAMD components. The model yields two outputs, binary classification (1/0) and the probability for each class. It is important to note that the data is unbalanced such that there are only 64 ins out of 300 or so teams per season, which is only around 22%. What's great about logistic regression is that the midpoint (bias parameter in the logistic function) does not have to be centered, reducing the overestimation of the slope parameter. The figure above shows the logistic regression done in terms of FAMD factor 0 (red dot showing Oklahoma) where the sigmoidal shape is visible with only one component. After the regression, predicted probability was sorted and top 64 were assigned 1. The validation accuracy was 88.2% with 0.719 sensitivity and 0.923 specificity where the chance level accuracy is 66.2%.
[Model 3] NCAA Tournament Ranking & WS Tournament of 8 Appearance
Now that I know the likelihood of my team making the NCAA tournament, two most important questions remain: (1) Can this team make WS tournament?; and (2) what is its most likely rank in the NCAA/WS tournament?
There are 9 classes of NCAA/WS tournament ranks - Champion, Finalist, Semi-finalist, Top 6, Top 8 (World Series), Top 16, Top 32, Top 48, Top 64. In order to predict how far a team makes into the tournament, multinomial classification model was developed. The model does not always assign fixed number of teams into each class, so sorting was done based on the model predictions. In other words, starting from the top class (Champion), teams were sorted according to the probability of being assigned to a rank class.
For each categories, Top 48 prediction achieved 68.75% accuracy, Top 32 achieved 84.4%, Top 16 achieved 75%, Top 8 achieved 50%, Top 6 achieved 66.7%, Semi-finalist prediction achieved 75%, and Finlaist prediction achieved 50% accuracy (chance level accuracy for Finalist prediction is 0.67%).
Data Visualization - Interactive Dashboard
Interactive dashboard was developed using Jupyter dash in order to help people navigate between past, present, and predicted future performance of a team. User can choose a college team to observe its stats (first tab) compared to the other teams as well as its projections (second and third tabs). Upon choosing a team, the sidebar displays the summary of the past performances between 2013 and 2018. In the main panel, average stats are displayed with offensive stats in warm colors and defensive stats in cool colors. Win/Loss percentage is shown in yellow. This representation shows the stats relative to the average of all teams, above or below average with top and bottom 5% grids available for reference.

The second tab contains RPI ranking projection for the team. Bootstrap with replacement of N=1000 was performed to generate the distribution of the possible outcomes. The range of the rank projection covers 25% and 75% quantiles.

The third tab contains the projections made from Models 2 and 3 related to NCAA Tournament. Top panel displays the Model 2 prediction, the likelihood of making into 64 teams to play in the tournament. Since it is imbalanced data, boostrap of N=1000 was performed with stratified resampling to estimate the probability distribution of the possible outcomes (chance making into the tournament).

The bottom panel contains several interpretations of Model 3 predictions. Based on 1,000 simulations, the cumulative probability of making into each category was estimated. Also, the most likely final placement was estimated as well as the likelihood of making into WS Tournament (Top 8).

Future Direction
This is a seed project for developing more comprehensive models to understand and make projections on women's college softball games. We wanted to first see if aggregate game stats can provide sufficient information to describe and predict long-term game performances such as tournament appearance and final placement. Relatively simple models were able to predict above chance levels with plenty room for improvement, indicating that more comprehensive models with per-game stats and individual player line ups can further increase the accuracy of the model.
Yorumlar